pcb-rnd knowledge pool
Schematics editor poll (2020)
| sch_poll_2020 by Tibor 'Igor2' Palinkas on 2020-11-23 | Tags: admin, poll, schematics, editor, 2020 |
Abstract: Poll results on "What's your preferred schematics editor when using pcb-rnd?". Multiple answers, ordered by frequency of use was possible.
Total number of answers: 17
Anonimized raw data is available in tsv (each line is a vote, fields are editors, feilds are separated by tab, first field is the most preferred editor).
First choice
List of editors as first choice (one vote = 1 point):
|
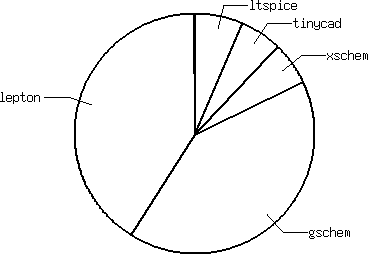
|
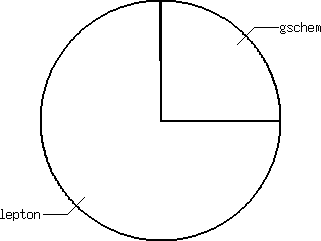
Second choice
List of editors as second choice (one vote = 1 point):
|
|
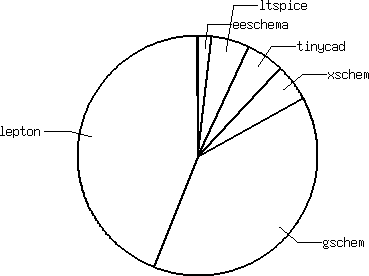
Combined/weighted
List of editors weighted by preference (first = 1point, second = 0.5 point, third = 0.25 point):
|
|
Number of editors used
How many users use 1 or 2 or 3 editors?
|
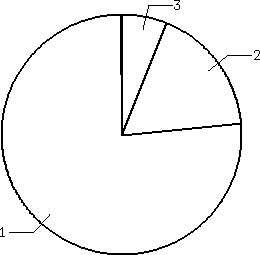
|