Porting methods
Porting software, when translated to the language of the end user, means that
the same source will compile and run on different systems. Different may
range from "different versions of the same operating system" (e.g. Linux
distribution) on the same hardware through "different operating systems
on different desktop and server machines" to "anything that has a file
system and a C compiler, from a 8 core gamer PC to an arm based
embedded system". The decision is up to the user (and the developer).
Normally my interpretation is: if it's manually hacked to work on
two or a few systems, it's cross-platform. If provisions have been
made for "compile and run on any system that has [list of requirements]" and
the infrastructure more or less works, I tend to use the term portable.
However, in this document I chose a very liberal interpretation and
define porting as "getting it to compile on at least one system". This will help
evaluating the different approaches, which are illustrated on the graph
below.
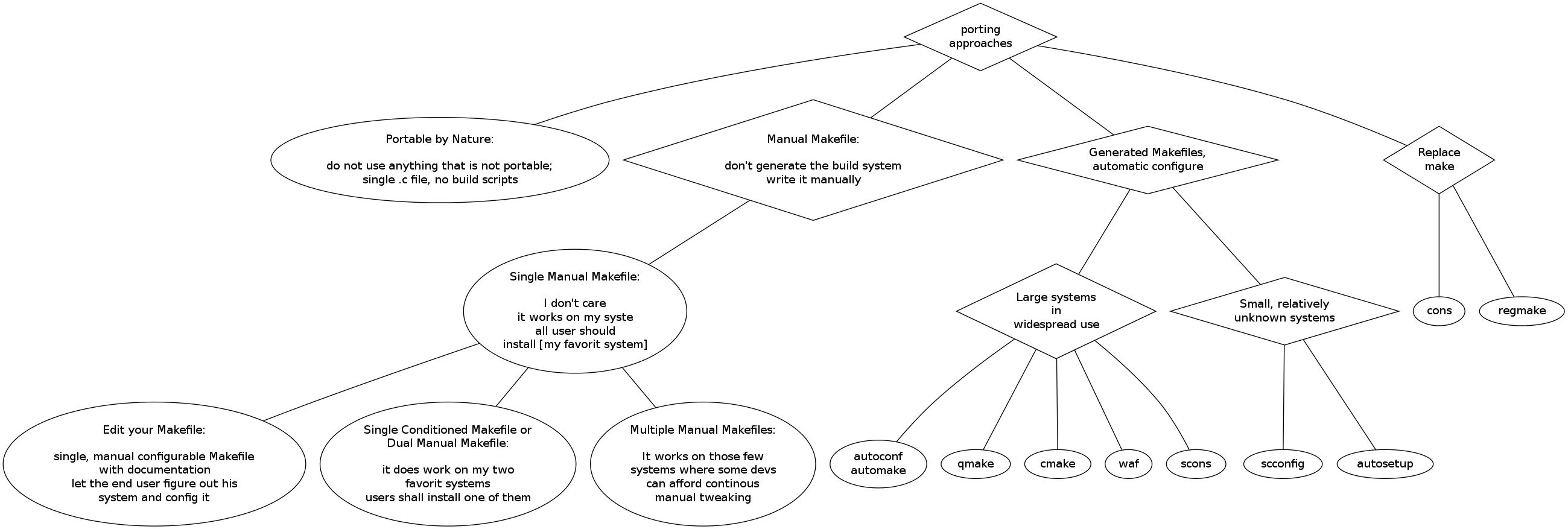
First, the developer needs to decide whether he needs to care much about porting.
1. Portable by Nature
The most convenient approach is when the code does not implement anything
that imply portability issues. For example a single file ANSI C program that
does not use anything than stdio, small integers and has absolutely
no assumption about the execution environment beyond these, falls under
this category. The single file requirement is strong: for a single file
the developer can simply say "compile and run it", without providing any sort
of a build system. This allows mostly everyone from GNU/Linux users to
whatever-proprietary-graphical-IDE users on Windows or Mac to compile the
software as well as real geeks running a System V derived UNIX released
in the early 90s.
But the price is high: it is extremely simple to accidentally incorporate
implications about the execution environment. For example if the software
opens files on the file system, it tends to assume various properties of
the file system - path separator is a common example. Or even just
calculating with integers: how wide an "int" is, while C89 doesn't
provide stdint.h?
A way to escape this trap is to use high level languages, such as shell,
awk, perl, python. However, this method has its own drawbacks. First of all,
the real common minimum for old languages such as shell and awk are very
low. For example awk has random limitation on string lengths, number of
fields, etc, set very low in many old implementations - and there
are a lot of implementations out there! Choosing a modern language
may promise to skip the hassle of implementations - most of them
have only one implementation available (the reasons for this is another,
very interesting story). But this also means the subject software is
only as portable as the one implementation of that language the developer
chose, and the developer can do very little about the portability of
the interpreter.
Nevertheless, this is a popular and working model in some domains. Typical
examples are demonstration of theoretical algorithms of research
papers (where stdio communication is all I/O the software ever does) and
extremely small and simple tools, also without I/O.
Growing code size doesn't help this method either. After a specific size,
programmers tend to restructure and split the code into multiple source files.
Manually compiling such a multi-file project is not what users prefer.
Pros: sometimes very simple but may be a PITA to keep this up for a larger project
Cons: no overhead - unless the software needs to do something more
2. Manual Makefile
When Portable by Nature didn't work, another method is chosen. If
the developer tries to ignore the problem, most often the Manual Makefile
branch is automatically selected. On the other hand, this can be a
deliberate choice of the developer. In the latter case the developer
refuses to chose another branch, most often for one or more of the
following reasons:
- the software doesn't need to be portable at all: special application,
limited user base or marketing strategy (e.g. some smartphone apps
that are developed solely for one smartphone family or expensive
CAD systems with "the end user uses Windows anyway" assumption or the
sole purpose of the software is to fix or extend a specific
operating system or even installation)
- the software can not be portable due to other limitations: drives
special hardware that is not available on other systems or a firmware or
kiosk software that will be run on specific platform only and when
the device is replaced, the software is replaced as well
- overhead of the other branches - the software could benefit
from portability (doesn't fall in any of the above categories), but
the developer decided against other branches because of the overhead
of the build system or even the overhead of programming in a portable
manner
The two major problems with this branch are:
- A. old, widespread build systems like make have a very low common minimum;
it's hard or impossible to write a working generic build script that works
everywhere; it's hard to maintain a verbose, dumb-but-works-everywhere
build script manually.
- B. system specific settings/properties/configuration for the software and
the build system needs manual configuration; doesn't scale well as number
of such settings increases
2.1. Single Manual Makefile
Probably the most common case is when the developer maintains a single
Makefile (or equivalent build script written in whatever language, including
the automatic build recipes of GUI IDEs). In this case the developer can
compile the code, or users who are willing to install the same (or very similar)
system. Because the user base will use the same system, these projects
tend to implement code that includes assumptions specific to that given system
on all levels. Thus these project are extremely hard to port.
Pros: simple, lazy method
Cons: won't work anywhere else
2.2. Edit your Makefile
When this starts to become an issue (sometimes even due to different
versions of the same operating systems or IDEs being used within the user
base), a natural extension is to structure the build scripts to
make system specific parts easy to edit/change. This often means the
code is grouped so that these settings are separated, and documentation
is provided.
This usually makes the project able to compile and run on a few systems,
mostly those that are close to the developer's. It requires ongoing
attention of the developer already: any new feature that may break
on other systems must be made configurable, grouped accordingly and documented;
this already has mentionable overhead compared to the previous method.
This method is extremely annoying for the end user: it assumes the user
knows a lot of little details about their system and is willing to spend
the time (ranging from minutes to hours) investigating and configuring just
to compile.
Pros: trivial upgrade from the single manual makefile, relatively low overhead
Cons: hassle to the user
2.3. Conditioned/Dual Makefile
A trivial upgrade is to collect the configuration for known systems, name
the systems and have a single system choice instead of manual configuration
of each individual property. This is commonly done by conditional parts
in the build scripts. An alternative is to have different set of build scripts
for each setup and let the user chose one of them (e.g. Makefile.linux,
Makefile.win32).
As long as the user is using a known system (i.e. one that the project
is already manually configured to), he doesn't need to change anything.
Or at least as long as enough of the library versions, dependencies and
system configurations match. The fallback is manual configuration, the
previous method.
This method scales very poorly, as any new version of the build scripts
takes some extra time during maintenance of the build system.
Pros: trivial upgrade from the Edit your Makefiles,
medium to large overhead, less hassle for majority of the users as long
as the user base tends to use a small number of systems
Cons: maintenance effort doesn't scale well; users with
slightly different system will have to fall back to manual configuration
2.4. Multiple Manual Makefiles
Essentially the previous method, already running wild. Such projects
have at least half dozen Makefiles from which some used to work
with older versions of the source but bitrotted along the road, others
do work with the source but failed to keep up with the changes in their
target systems.
Pros: "at least build scripts are not generated" and "works for most of my users out of the box"
Cons: doesn't work for minority of the users; maintenance cost is high; confusing for the user
3. Replace Make
Replacing make, or any other (relatively) simple build tool with a more complex
one may solve problem 2/A, which already makes maintenance much easier.
However, it does not solve 2/B - so these solutions tend to end up advanced
versions of branch 2 with reduced maintenance cost.
On the other hand this brings in new dependency which may reduce overall
portability of the software; make is still more available than its
replacements, on exotic systems.
3.1. regmake - case study
Regmake is an abandoned make replacement project. It aimed to be small,
simple and portable and tried to fix the problems of recursive make
and tricky pattern matching (the latter by using regexp, thus the name).
After the prototype started to work, I realized regmake could not solve 2/B.
This means using regmake alone doesn't work and another system is needed
for configuring the software and potentially the build system, which certainly
leads back to the 2/B portability problem that seem to have three solutions:
- single file Portable by Nature project (1.) - clearly not the case if make didn't work
- manual configuration (2.) - in this case using regmake over make offers marginal gain when there are already more than 2 or 3 set of configurations
- automatic configuration (4.) - results in generated files; once there are generated files and an extra step already, the benefit of having the build script static is not that important
Pros: easier to write "clever" (complex), maintainable build scripts
Cons: does not solve multiple manual or generated config problem
3.2. cons
Another long abandoned project is cons. It's a make replacement with
a lot of extra features, written in perl. While it suffers from the same
problems as regmake, it also introduces a new dependency: perl. Depending
on another generic programming language has its pros and cons. While
it makes the system more flexible for those who already master the language,
it my be a burden for developers who do not.
4. Generated Makefiles, Automatic Configuration
A common method for solving both 2/A and 2/B is to generate the build scripts
(most often Makefiles), combined with a tool to automatically detect system
dependent properties for the configuration. When it's not buggy, it frees
the user from manual configuration and can use the oldest, most common
make syntax: generated Makefiles don't need to be clever or small, the
input files need to be.
This comes at a cost, tho:
- the overall overhead of the system is large compared to the simplest
methods in 2.; however, it scales better, in case of software ported
to many systems may be cheaper than manual configuration
- there is an extra layer; whenever the developer needs to modify the build
scripts, the configure tool needs to be run again
- with some implementations the clever high level build-script-input language
considerably limits the developer to one or at most to a few patterns the
tool supports
For this purpose there are more widespread, usually large systems and
less known or even abandoned, usually smaller systems.
4.1. Large: autoconf, automake
The autotools system is a heavyweight implementation. It has capabilities
to generate configuration detection scripts and makefiles. It heavily
builds on an old (widely available) scripting language, m4.
When it works, it helps building relatively portable software;
it's huge, maintenance cost is high. Whenever it breaks down, it most
often takes more time to fix it than to do the manual configuration.
M4 is a real burden as less and less developers know the language, not
to mention users (who are typically the ones who face breakdowns when
trying to configure the system).
My personal experience is that the average autotools project is portable
only among a few modern systems, and most often breaks on anything marginally
exotic. This is usually blamed on the software being configured, not on
autotools itself - but such common misuse of the tool suggests problems
in the tool.
Pros: widespread, widely known and accepted by developers and users, has the potential to efficiently help making software portable
Cons: extremely large maintenance costs; when breaks, the user is in worse position than with 2.2.
4.2. Large: qmake, cmake
These systems offer a much more abstract language for describing the build.
This makes it easier to express complicated structure of the project but
also limits what can be expressed. After a while, for a complex project
with special rules that would be easy to write in a traditional Makefile,
a lot of extra effort is spent on trying to explain the build system
what to do.
TODO
4.3. Small: scconfig
Scconfig does not depend on m4 and does not offer a custom high level
abstraction above the build. It's implemented in plain ANSI (C89) C,
and is a framework for auto detecting system properties. Once the
detection phase is done, all properties are collected in a hierarchical
database.
The next step is to generate the necessary build scripts and source
files (e.g. config.h). For this the developer has five choices:
- A. write ANSI C code that simply prints the files
- B. write ANSI C code that reads templates and generates the files
- C. use generator, the builtin dumb templating language
- D. use tmpasm, the builtin clever templating language
- E. a combination of A, B and C or A, B and D.
Pros: literally no dependencies; the only language the developer must know is C; small, simple, modular; does not restrict how build scripts are generated (templating instead of abstract build language); small enough that the full scconfig source can be embedded in the source tree of the target software
Cons: does not offer blind porting, requires the developer to understand many aspects of porting
4.4. Large: Scons
TODO
4.5. Small: autosetup
TODO
Can be deployed directly in the project source tree. Output generation
is not general, but tailored to Makefile and config.h. Depends on tcl.
4.5. Large: Waf
Heavyweight application that controls the whole process of configuration
and build, implemented in python.
TODO